 Stephen Young
Stephen Young
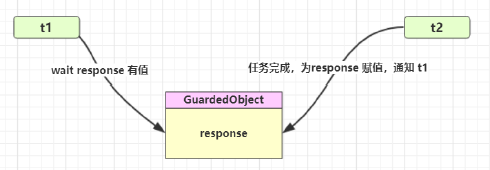
Guarded Suspension
即保护性暂停,用在一个线程等待另一个线程的执行结果
要点
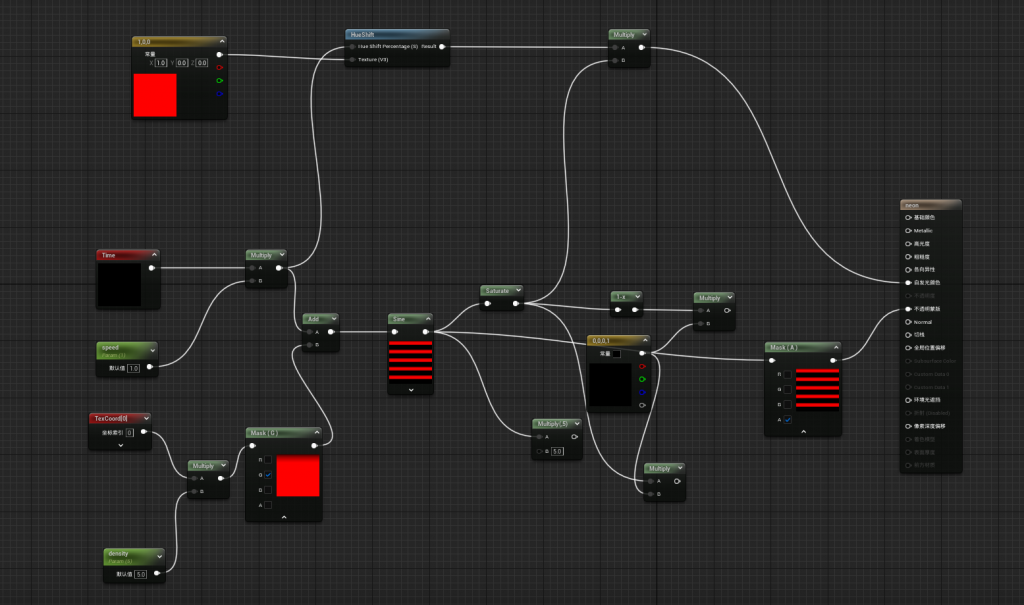
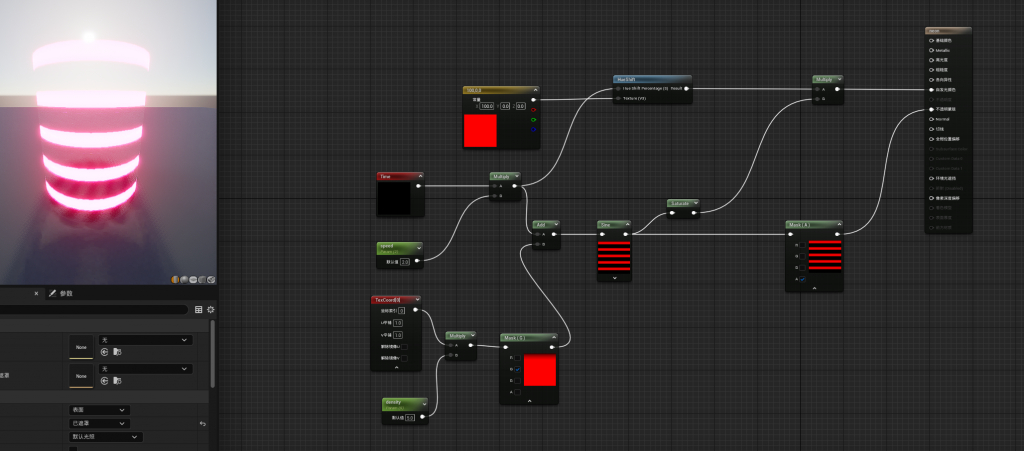
守护类
package tech.ityoung.study.demo.jvm.juc;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class GuardedObject {
private Object lock = new Object();
private Object response = null;
public Object get(long waitTime) {
synchronized (lock) {
long begin = System.currentTimeMillis();
long start = 0;
while (response == null) {
if (waitTime - start <= 0) {
break;
}
try {
lock.wait(waitTime - start);
} catch (InterruptedException e) {
e.printStackTrace();
}
long now = System.currentTimeMillis();
start = now - begin;
}
log.info("get response completed");
return response;
}
}
public void complete(Object response) {
synchronized (lock) {
while (response != null) {
this.response = response;
lock.notifyAll();
break;
}
}
}
}
测试类
主线程等待子线程返回结果
等待时间内如果返回结果,则wait提前结束,否则wait时间后结束返回null
package tech.ityoung.study.demo.jvm.juc;
import lombok.extern.slf4j.Slf4j;
import java.util.Random;
@Slf4j
public class GuardedObjectTest {
public static void main(String[] args) throws InterruptedException {
log.info("starting demo");
GuardedObject guardedObject = new GuardedObject();
new Thread(() -> {
int response = 0;
try {
response = getResponse();
} catch (InterruptedException e) {
e.printStackTrace();
}
guardedObject.complete(response);
}).start();
Object o = guardedObject.get(5000);
log.info("getting finished: {}", o);
}
private static int getResponse() throws InterruptedException {
Thread.sleep(4000);
return new Random(5).nextInt();
}
}
仓廪实而知礼节 衣食足而知荣辱
————评《丑陋的中国人》中的胡说八道
RSS订阅测试
日期属性加上
@jsonformat(pattern = timezone =
String str = System.getProperty(“user.dir”)
unicode是一个字符集,里面几乎包含了目前世界上已知的所有字符,且该字符集将二进制代码和字符形成一一映射,即一个字符对应且只对应一个二进制代码,反过来,一个二进制代码对应且只对应一个字符。如果我们有一个字符,那么通过Unicode字符集很容易找到该字符对应的二进制码,但是,反过来,可能会出现混乱,为什么呢?情境如下:如果我们假设Unicode字符集有两个字符,比如说(这里我没有查阅Unicode字符集,虚构了两个,只是打个比方,请各位看官不要较劲):1100 1111 1111 0001 1111 0101 对应字符‘我’,一共三个字节,1100 1111 1111 0001对应字符‘你’,一共两个字节,恰好是‘我’这个字符二进制码的前两个字节。如果我们存的是‘我’即三个字节的那个代码,即1100 1111 1111 0001 1111 0101,然后让计算机进行解码时,它会从左向右依次读取一个数码,当读到1100 1111 1111 0001时它可能就停止,让‘你’这个字符与其对应,并不是我们当初想存的‘我’这个字符,只是因为这两个字符对应的二进制码前两个字节是一样的,这就是一个问题。Unicode字符集中对字符的编码是长度不确定的,其中有的字符是两个字符,有的是三个字符,这给计算机进行解码带来了困难(就像上述描述的情境),所以我们想给每个字符对应的二进制码前加上一个标记,让计算机看到这个标记就知道它将要读取几个字节,这样就防止了上述描述的两个字符因为前两个字节编码相同而误将三个字节的字符当成两个字节的字符读取了这种错误,那么这个标记该怎么加呢?这就导致人们引入UTF-8,它的英文全称是8-bit Unicode Transformation Format,可以看出它是将原本的Unicode码进行了transformation,这种transformation 就是给每个Unicode码进行标记,使得让计算机看到某个标记就知道待会要读取几个字节的代码,从而避免问题发生。因此,我觉得utf-8的引入,最主要的原因不是楼主所说的“一切都是为了节省你的硬盘和流量”,最重要的是避免我刚才所描绘的情景所发生的错误。以上文字内容,如有逻辑不正确的地方,请批评指正,我会耐心接受,谢谢